
Get a summary footprint on a MySQL server instance

I've built a simple script, scraping from here and there, to gather a summary of relevant information.
Once you've gained remote access to the MySQL instance, you can execute the queries to identify the following information regarding the target database server:
- The host name, what operating system it runs on, the MySQL version installed, default collation of the instance, the installation directory and the data directory;
- How many user databases it hosts, what they're called and the collation used;
- The size of each database as a whole and broken down by storage engine;
- All the tables and their space used ;
- The creation and last modification on each database.






Get a summary footprint on a MySQL server instance
Link: Get a summary footprint on a MySQL server instanceLanding on an enterprise with ongoing projects mean that servers are often handed to IT staff without complete knowledge of what’s inside.
I’ve built a simple script, scraping from here and there, to gather a summary of relevant information.
JSON on MySQL: still not fond of it.
Earlier, I posted here about my dislike of allowing developers to push the JSON workload into the database server.
Reading this entry on a nice blog about MySQL, what caught my eye was the sentence:
Funny. It all started with the idea to be schema-free. Now people seem to need schema enforcement.
I’ve also seen this article on DZone which sarcastically illustrates the mislead of developers caused by the hype on JSON:
That’s it, then; let’s use JSON and manifest the death of XML!
I got reassurance on Twitter that MySQL performance won’t be compromised for using the new JSON datatype and operations:
@mjlmo I would like to see it be inc. in the standards (where it is currently being discussed). Overhead is well amortized by IO on insert.
— morgo (@morgo) September 10, 2015Not wanting to flog a dead horse here, by coming back to this topic, but it’s really not about the features or how they perform well on the engine. It’s what developers come up with to make things work.
Apparently, already there are bright minds that would like to cripple the flexibility of JSON with a sort of schema validation. Who knows what else will come up? And since the door is open to shove all that bright ideas inside the database engine, might as well make developers at home and put it up to them to solve the upcoming performance issues later on.
Configuring and testing MySQL binary log
The binary log contains “events” that describe database changes. On a basic installation with default options, it's not turned on. This log is essential for accommodating the possible following requirements:- Replication: the binary log on a master replication server provides a record of the data changes to be sent to slave servers.
- Point in Time recovery: allow to recover a database from a full backup and them replaying the subsequent events saved on the binary log, up to a given instant.
#Enabling the binary log
log-bin=binlog
max_binlog_size=500M
expire_logs_days=7
server_id=1- Binary log is turned on and every file name will be 'binlog' and a sequential number as the extension;
- The maximum file size for each log will be 500 megabytes;
- The binary log files expire and can be purged after 7 days;
- Our server has 1 as the identification number (this serves replication purposes but is always required).
shell> sudo service mysql restart
mysql> show binary logs;
+---------------+-----------+
| Log_name | File_size |
+---------------+-----------+
| binlog.000001 | 177 |
| binlog.000002 | 315 |
+---------------+-----------+
2 rows in set (0.00 sec)
- sakila-schema.sql: creates the schema and structure for the sakila database;
- sakila-data.sql: loads the data into the tables on the sakila database.
shell> mysql -u root -p < sakila-schema.sql
mysql> flush binary logs;
Query OK, 0 rows affected (0.01 sec)
mysql> show binary logs;
+---------------+-----------+
| Log_name | File_size |
+---------------+-----------+
| binlog.000001 | 177 |
| binlog.000002 | 359 |
| binlog.000003 | 154 |
+---------------+-----------+
3 rows in set (0.00 sec)shell> mysql -u root -p < sakila-data.sql
mysql> show binary logs;
+---------------+-----------+
| Log_name | File_size |
+---------------+-----------+
| binlog.000001 | 177 |
| binlog.000002 | 359 |
| binlog.000003 | 1359101 |
+---------------+-----------+
3 rows in set (0.01 sec)
shell> sudo mysqlbinlog --verbose /var/lib/mysql/binlog.000003Using the verbose option, the following commented output is produced from our log, one per each statement:
### INSERT INTO `sakila`.`country`
### SET
### @1=1
### @2='Afghanistan'
### @3=1139978640MariaDB Enterprise Cluster in Microsoft Azure Marketplace
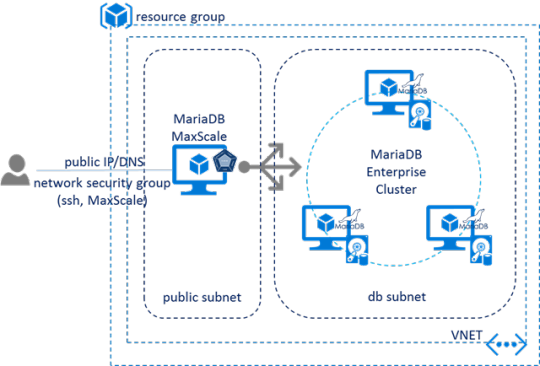
MariaDB Enterprise Cluster with Galera technology is a multi-master cluster that achieves high availability and scalability through features such as synchronous replication, read and write to any cluster nodes without slave lag, automatic membership control of new nodes joining the cluster and failed nodes dropping from the cluster.

This is why you're not better off with a commercial database
When tackling a new enterprise project to support a given business, you face the challenge of choosing and committing to a database platform. The choice should be the one most adequate, given the needs and requirements of the new information system and data to be hosted and managed.Typically, a number of factors should be taken into consideration like security features, storage requirements, reliability, high availability, backups, disaster recovery, data compression, technical support and last but definitely not least, the cost of the solution. Added to that there is also performance, scalability and ease of administration to think about.
With the result of this analysis, most of the time, the verdict is this: data platforms available as community editions or free open source fall short on the given requirements fulfillment. So, the advice is almost always to acquire commercial licenses or expand the licensing already owned.
And this should give you peace of mind for a while. At least until the first release of the system goes live. After that, some of the common pitfalls are:
- Security permissions were not exhaustively identified for all database objects. To solve things quickly, you turn your database authorization management into Swiss cheese;
- The new system has issues, until the bugs are fixed, manual correction scripts have to be executed on working hours, maiming overall business activity;
- As the data volume grows, there is performance degradation due to inefficient indexing, bad user experience design or poor database coding skills;
- Technical support provided by the database vendor performs an audit on the workload, does some tuning on the server instance, and shifts responsibility on the remaining lack of performance over to the development team;
- The development team struggles adopting the database vendor recommendations as it has great impact on the source code;
- Management wants high availability, but it won't commit the infrastructure resources and budget to set it up properly;
- You do not have a remote site so that a disaster recovery plan can be made, you don't have a lab where you regularly restore backups and perform automated integrity checks;
- You are understaffed and with no one possessing deep skills on the specific data platform you own;
Even if just a third of these pitfalls sound familiar, what are you doing with your next project? Still thinking on recommending commercial software because people are the ones to blame here?
On a global organization, after you deploy the first release and spread it across the offices, the licensing and support costs will skyrocket. That money could be spent preventing some of the pitfalls mentioned here. If you cut back on licensing and support, you can spend on infrastructure and staff.
There are wonderful commercial databases out there, but on the business requirements phase, the pick should be done as a whole and not based on vendor promises because the final solution will be a result of development and available budget, not a sales brochure.
Vision and engineering are the keys to success. And I'm afraid that doesn't come out of the box.
No comments :
Post a Comment